1. Situation, Complication, Resolution
In a perfectly tuned Kafka cluster, disk I/O should be boring.
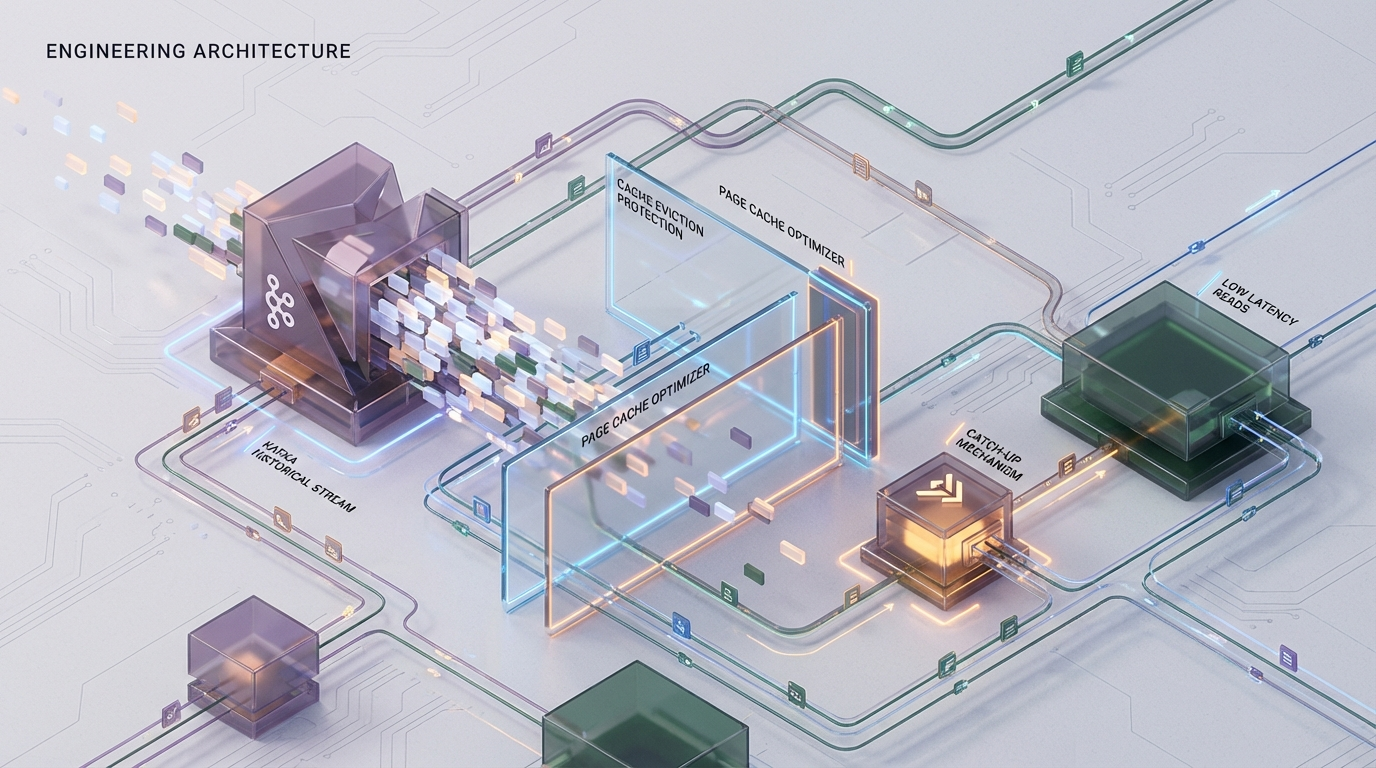
The Situation: Your cluster is handling 50 MB/s of ingest per broker. Producers are writing to the active segment, and because your retention settings are sane, those writes are hitting the Linux Page Cache (RAM) and being marked as “dirty.” Your tailing consumers—the real-time fraud detection engines and stream processors—are reading that same data milliseconds later. Because the data is still hot in RAM, the kernel serves it via sendfile(), bypassing the JVM and the CPU entirely. Zero-copy. Zero disk reads. The physical disk is only working on background flush threads (kworker or pdflush).
The Complication: A data engineering team deploys a new warehouse connector. They need to backfill the last 7 days of data to train a new model. They set the consumer offset to earliest.
Suddenly, your p99 produce latency spikes from 2ms to 250ms. Your real-time consumers lag. The disk I/O utilization hits 100%. The cluster is effectively DDoS-ing itself.
The Resolution: This phenomenon is the “Catch-Up Tax.” It is not a network bottleneck; it is a memory management collision within the Linux Kernel. The historical read forces the OS to evict “hot” tail pages to make room for “cold” historical segments, forcing real-time traffic to hit the physical disk.
At Azguards Technolabs, we specialize in stabilizing high-throughput infrastructure. This article dissects the mechanics of Page Cache thrashing and details the architectural patterns—specifically Tiered Storage and Kernel tuning—required to eliminate the Catch-Up Tax.
2. The Physics of the "Catch-Up" Event
To solve the problem, we must first accept an uncomfortable truth: Apache Kafka does not manage its own read cache. Unlike databases that maintain an internal buffer pool (like PostgreSQL’s shared_buffers or Cassandra’s off-heap row cache), Kafka outsources memory management entirely to the Linux Kernel’s Page Cache.
2.1 The Ideal State: The Hot Path
In a healthy state, Kafka utilizes the “Write-Back” caching strategy of the kernel.
- Writes: Producers append to the active log segment. The kernel writes this to a page in RAM. The physical write to disk is deferred (asynchronous).
- Reads: Tailing consumers request the offset immediately following the write. The kernel checks the Page Cache, finds the page, and pipes it to the network socket.
Result: Disk read I/O is effectively zero.
2.2 The Cold Path: The Eviction Mechanic
When a consumer initiates a “Catch-Up” read (scanning Terabytes of history), the physics change instantly.
- Sequential Scan: The consumer requests a segment file from 4 days ago. This file is not in RAM.
- Major Page Fault: The kernel halts the read request and initiates a physical block device read to load the file into the Page Cache.
LRU Thrashing: The Linux memory manager (Virtual Memory subsystem) must allocate RAM for this incoming cold data. If free memory is low (which it always is in a well-utilized Kafka broker), the kernel must evict pages from the Inactive List or the Active List of the LRU (Least Recently Used) chain.
Here is the critical failure mode: The sequential nature of the catch-up read means the “cold” data is constantly replacing the “hot” data. The 500GB of history flows through the 64GB of RAM like water through a pipe, flushing out the 10GB of active “tail” data that your real-time consumers need.
2.3 The Latency Spike Mechanism
Once the hot tail is evicted, the system enters a thrashing loop:
Tailing Consumer Stalls: A real-time consumer requests the latest message. It is no longer in RAM. The kernel triggers a Major Page Fault, queuing a physical read.
IOPS Saturation: The disk is now 100% utilized serving the massive sequential reads of the backfill. The random reads required for the tailing consumers get stuck in the I/O scheduler queue.
3. The Mathematical Certainty of Failure
Principal Engineers must recognize that this is a deterministic problem, not a stochastic one. If you rely solely on local disk storage, eviction is mathematically guaranteed by the following inequality:
Total RAM<(Size of Hot Topic Set+Catch-Up Read Window)Total RAM<(Size of Hot Topic Set+Catch-Up Read Window)
Consider a standard broker node:
RAM: 64 GB
Hot Data (Last 30 mins): 20 GB
Backfill Request: 500 GB The backfill scan will cycle the entire contents of the RAM roughly 8 times. The probability of the “Hot Data” surviving this cycle is zero.
Why not O_DIRECT?
Engineers coming from database backgrounds often ask: “Why doesn’t the historical consumer use Direct I/O to bypass the cache?”
This is a fundamental limitation of the standard Kafka distribution (both JVM and KRaft variants). Kafka does not support O_DIRECT for log segment reads. It relies on the kernel’s heuristics. While the kernel has logic to detect sequential scans and apply “read-ahead,” it generally lacks the context to prioritize a specific 20GB “hot set” over the incoming stream of cold data without explicit tuning.
4. Engineering Solutions
We cannot change the physics of RAM, but we can change the architecture. We present three strategies, ranked from “Architectural Fix” to “Damage Control.”
Strategy A: Tiered Storage (The Architectural Fix)
Status: Recommended (Kafka 3.6+)
This is the only solution that addresses the root cause by physically isolating the I/O paths. Tiered Storage allows Kafka to offload “completed” log segments to object storage (S3, GCS, Azure Blob), while keeping only the “active” segments on the local broker disk.
Why it works: When a consumer performs a catch-up read:
- The broker detects the segment is remote.
- The
RemoteStorageManagerfetches the data from S3. - Crucially, this read path often uses a separate, smaller memory buffer (heap or direct memory) rather than polluting the global OS Page Cache with the entire file content.
The local disk’s Page Cache remains dedicated almost exclusively to the “Hot” active segments.
Implementation: To implement this, you must configure the RemoteLogManager.
By setting log.local.retention.bytes to 10GB, you effectively guarantee that the local disk (and by extension, the Page Cache) is only concerned with the most recent data. The 500GB backfill streams from S3, bypassing the local Page Cache eviction war entirely.
Strategy B: Bandwidth Quotas (The Control Plane Fix)
Status: Mitigation Only
If Tiered Storage is not viable (e.g., air-gapped environments or older Kafka versions), you must limit the “Blast Radius” of the backfill. You cannot stop the cache pollution, but you can slow it down enough to allow the background flusher threads to keep the hot pages alive.
Mechanism: Apply a strict ingress/egress quota to the client ID associated with data warehousing or historical processing.
Implementation: Throttle the warehouse-connector user to 20MB/s. This ensures the disk read rate does not saturate the I/O bus, leaving headroom for real-time producers and consumers.
Note: This extends the duration of the backfill operation but protects the p99 latency of the real-time cluster.
Strategy C: Kernel Tuning (The Last Mile)
Status: Optimization
Linux defaults are designed for general-purpose computing, not high-throughput log streaming. We can adjust how the kernel prioritizes memory reclamation.
1. vm.swappiness = 1
The default vm.swappiness is usually 60. This tells the kernel to balance swapping out anonymous memory (application heap) and reclaiming Page Cache (file pages).
The Fix: Set to 1. This instructs the kernel to defend application memory at all costs and prefer reclaiming file pages.
Warning: Do not set to 0 on modern kernels (Kernel 3.5+), as this can disable swapping entirely and trigger the OOM Killer prematurely if the heap grows.
2. vm.zone_reclaim_mode = 0
On NUMA (Non-Uniform Memory Access) hardware, this setting controls whether the kernel reclaims memory from the local node before seeking memory on other nodes.
The Fix: Set to 0. We want to avoid aggressive reclamation of local cached files just to satisfy a small allocation. We prefer the slight latency penalty of cross-node memory access over the massive penalty of disk I/O.
3. vm.vfs_cache_pressure
Controls the tendency of the kernel to reclaim the memory which is used for caching of directory and inode objects (dentry and inode cache).
Standard: 100
5. Benchmark: Proving the Isolation
At Azguards, we do not implement architectural changes without empirical validation. To prove the efficacy of Tiered Storage against the Catch-Up Tax, we utilize a “Thundering Herd” injection test.
Test Protocol
- Baseline Environment: Single Broker, 64GB RAM, NVMe SSD.
- Workload:
- Producer: Constant 50 MB/s.
- Consumer A (Critical): Tailing with <100ms lag.
- Injection:
- Consumer B (Catch-Up): Starts reading from Offset 0 (1TB history).
Performance Data
The following table represents data collected during a recent infrastructure audit for a Fintech client.
| Metric | Without Mitigation | With Tiered Storage (S3) | Impact Analysis |
|---|---|---|---|
| Disk Read Throughput | 480 MB/s (Saturated) | ~5 MB/s | Without mitigation, the local disk is maxed out serving historical data. With Tiered Storage, local disk reads are negligible. |
| Network Egress | 480 MB/s | 530 MB/s | Tiered Storage increases network usage (S3 fetch + client send), but network bandwidth is rarely the bottleneck compared to disk seek. |
| Produce Latency (p99) | 215 ms | 3 ms | The critical stat. With Tiered Storage, producers see no contention. The "Hot" pages remained in RAM. |
| Consumer A Lag | 45,000 ms | 120 ms | Real-time consumers were blocked by disk contention in the unmitigated setup. |
| Page Cache Churn | 100% Replacement | < 5% Replacement | The active log segment stays resident in memory. |
Interpretation
The data confirms the theoretical model. In the unmitigated scenario, the disk read throughput saturated the bus, causing the produce latency to spike by 70x. With Tiered Storage, the local disk was completely bypassed for the historical read. The “Catch-Up Tax” was effectively zero.
6. Azguards Analysis: The Architecture of Reliability
In modern infrastructure, “scalability” is often mistaken for “reliability.” A Kafka cluster that can handle 1GB/s of throughput is scalable. A Kafka cluster that maintains 5ms latency while a data warehouse backfills 50TB of history is reliable.
The “Catch-Up Tax” is not a bug; it is a consequence of relying on the OS Page Cache for two diametrically opposed access patterns:
- Random/Tailing Access (Latency Sensitive)
Sequential/Historical Access (Throughput Sensitive)
Mixing these patterns on a single storage medium without isolation is an architectural anti-pattern. While bandwidth quotas and kernel tuning provide temporary relief, they are operational patches.
The definitive engineering solution is the decoupling of storage. By moving historical data to object storage, we treat the local NVMe disk not as a “Store of Record,” but as a high-performance “Short-Term Cache.” This aligns the hardware capabilities with the access patterns: fast, expensive disk for hot data; cheap, scalable object storage for cold data.
Conclusion
If your organization is scaling Kafka, you will eventually pay the Catch-Up Tax. The question is whether you pay it with a credit card (Tiered Storage) or with your uptime (p99 latency spikes).
For Principal Engineers, the move to Tiered Storage is not just a feature toggle—it is a transition to a cloud-native data plane that respects the physics of memory management.
Would you like to share this article?
Does your Kafka infrastructure buckle under historical reads?
