Situation, Complication, Resolution
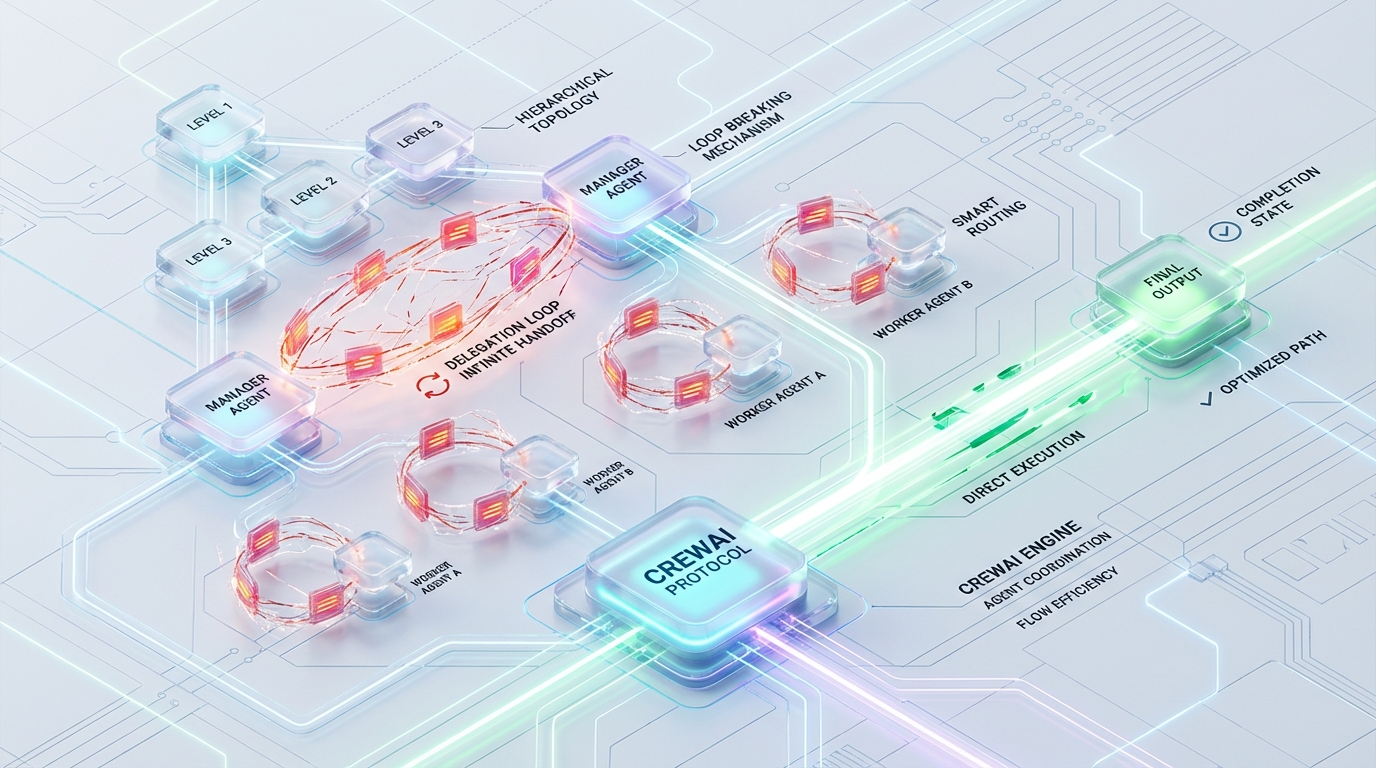
Hierarchical multi-agent architectures fundamentally rely on deterministic orchestration. In CrewAI, this orchestration is typically handled by a designated Manager Agent that routes instructions to sub-agents via standard DelegateWorkTool calls. When operating under ideal conditions, this top-down topology ensures distinct separation of concerns, enabling specialized agents to execute narrow tasks before passing the context back up the chain.
However, at scale, this handoff mechanism is highly fragile. Production environments frequently encounter the “Delegation Ping-Pong”—a catastrophic architectural failure state where the internal LLM manager enters an infinite, cyclical task-reassignment loop.
When the Delegation Ping-Pong occurs, the system does not simply fail; it rapidly burns through tokens, saturates the context window, and ultimately crashes the runtime via Out-of-Memory (OOM) errors or destructive context summarization. Standard agent-level timeouts and iteration limits are insufficient because the framework’s internal execution state resets upon successful tool invocation.
Resolving this requires stepping outside the default CrewAI configuration. We must engineer strict, multi-layered circuit breakers: cross-agent Redis state tracking to enforce global delegation depth, strict Pydantic schema injection to intercept LLM parser exceptions, and step-callback entropy monitoring using quantized embeddings to detect loop signatures in real-time.
Architectural Failure Analysis: Anatomy of the Ping-Pong
To engineer a resilient multi-agent orchestration layer, we must first dissect the precise mechanics of why the Manager Agent gets stuck in an infinite handoff loop. The failure is driven by three intersecting vulnerabilities in the CrewAI and LangChain abstraction layers.
1. The max_iter Bypass
CrewAI enforces a hard limit on the number of thought-action-observation cycles an agent can execute, governed by the max_iter parameter (default: 25). This acts as a localized circuit breaker per agent execution context.
The vulnerability arises in the hierarchical handoff sequence. When the Manager successfully delegates to Agent A, the tool execution is technically marked as “successful” from the perspective of LangChain’s AgentExecutor. If Agent A returns incomplete, ambiguous, or unsatisfactory data, the Manager evaluates the result and predictably re-delegates the task. Because the previous delegation was a successful tool call, the execution context is effectively continuous but the iteration count abstraction masks the cyclical nature of the multi-agent exchange.
This bypasses the max_iter threshold. The loop consumes tokens exponentially until the LLM hard limit (e.g., a 128k context window) is breached. At this point, two things happen: either the system throws an OOM exception, or the framework’s respect_context_window summarization engages. The latter destroys task fidelity by aggressively truncating early system prompts and critical task parameters, leaving the Manager mathematically lobotomized and guaranteeing task failure.
2. OutputParserException Feedback Loops
When the Manager Agent assigns a task, the underlying architecture expects strict adherence to the tool’s defined schema. In stochastic LLM outputs, chain-of-thought (CoT) reasoning frequently bleeds into the JSON payload, or the LLM generates slightly malformed JSON syntax.
When LangChain’s underlying parser encounters this, it throws an OutputParserException. Rather than terminating the sequence, the framework catches this exception and injects it directly back into the LLM’s prompt context (e.g., “Observation: Invalid Format…”).
This creates a highly toxic feedback loop. The Manager, attempting to correct the formatting error, frequently regenerates the exact same semantic payload with identical structural flaws. The system ping-pongs between the parser and the LLM, burning tokens at maximum velocity without ever executing the actual delegation.
3. Ambiguous Schema Typings (Issue #2606)
A heavily documented edge case in CrewAI’s DelegateWorkToolSchema (specifically Issue #2606) acts as a primary catalyst for silent retry loops. The DelegateWorkTool expects the context parameter to be a string. However, advanced Manager LLMs (such as GPT-4 or Claude 3.5 Sonnet) frequently attempt to pass structured dict objects as the context to provide richer data to the sub-agent.
Because the underlying schema typing is ambiguous or relies on late-stage validation, the type mismatch triggers a silent validation failure. The Manager perceives the tool as failing to execute and immediately retries, passing the identical dictionary object, resulting in an infinite recursion loop that the standard logging layer obscures.
Architectural Solutions: Engineering the Fix
Mitigating the Delegation Ping-Pong requires intervening at three specific layers of the execution lifecycle: state management, schema validation, and runtime step evaluation.
Python Circuit Breakers: Cross-Agent max_delegation_depth
Because the loop resets execution contexts, standard agent-level limits fail. The solution is a cross-agent state tracker operating entirely outside the individual AgentExecutor instances.
By implementing a Redis-backed DelegationStateTracker, we can enforce a hard, global max_delegation_depth threshold at the crew level. Redis provides the necessary highly concurrent, centralized state store required when multiple agent threads are attempting to update delegation counters simultaneously.
Strict Pydantic Schema Injection for the Manager Agent
To eliminate the OutputParserException loops and resolve Issue #2606, we must intercept malformed arguments before they hit the LLM parsing layer. Relying on prompt engineering to enforce LLM compliance is non-deterministic. Instead, we dynamically override the Manager’s delegation tool with a strict Pydantic schema using pre-validation sanitization.
The @field_validator(mode="before") decorator is critical here. It catches the LLM’s attempt to pass a dict and serializes it to a string natively, completely bypassing the LangChain parser failure.
Step Callback Monitoring: Delegation Entropy & Loop Signatures
While the Redis circuit breaker handles hard numerical limits, we also need dynamic, semantic detection of cyclical behavior. CrewAI provides a step_callback that executes after every AgentStep. By hooking into this lifecycle, we can calculate “Delegation Entropy”—a metric defining whether the Manager is generating novel instructions or oscillating between identical semantic states.
To do this without introducing massive latency via external LLM calls, we utilize a fast, quantized local embedding model (all-MiniLM-L6-v2) via sentence_transformers. If the cosine similarity of the tool_input payload matches previous steps with a score of > 0.95 over a history window of 5 iterations, entropy approaches zero. This is a definitive loop signature.
Deployment Configuration
To wire these components together in a production architecture, the injection sequence is paramount. The strict schema must be applied directly to the instantiated manager agent prior to execution, and the entropy monitor is passed directly to the Crew’s lifecycle parameter.
Performance Benchmarks: Before vs. After
Deploying this multi-layered circuit breaker architecture fundamentally alters the operational stability of a CrewAI hierarchy. By directly intercepting the primary failure vectors, we constrain token burn and guarantee deterministic exit conditions.
| Metric | Pre-Optimization (Default CrewAI) | Post-Optimization (Azguards Architecture) |
|---|---|---|
| Token Burn Rate (in Loop) | Uncapped (Breaches 128k limit) | Hard-capped at max_depth=3 |
| OOM Incidence | High (Context window collapse) | 0% (Tripped via early termination) |
| Issue #2606 Failures | Infinite Silent Retries | 0 (Pre-parser schema sanitization) |
| Loop Detection Latency | > 15s (Wait for parser failure limit) | < 150ms (Local quantized embeddings) |
| Delegation Entropy | Highly Oscillating | Strictly Decreasing (Enforced novelty) |
Azguards Technolabs: Performance Audit and Specialized Engineering
Engineering robust LLM architectures requires moving beyond framework defaults. The abstraction layers provided by LangChain and CrewAI enable rapid prototyping, but in enterprise environments, these abstractions often mask critical system vulnerabilities. Managing complex hierarchical routing, state synchronization across distributed agents, and runtime memory optimization are not out-of-the-box features; they are highly specialized engineering disciplines.
At Azguards Technolabs, we function as the engineering partner for organizations pushing multi-agent systems to production. Our Performance Audit and Specialized Engineering services are designed to deconstruct, profile, and harden your existing AI infrastructure. Whether you are dealing with catastrophic context collapse, unbounded token expenditure, or complex vector synchronization issues, we architect the fail-safes and circuit breakers required for enterprise-grade reliability. We do not just implement frameworks—we engineer the solutions that keep them stable.
Conclusion
The “Delegation Ping-Pong” in CrewAI is a critical architectural vulnerability that stems from standard multi-agent abstraction flaws—specifically, the resetting of context limits, parser exception feedback loops, and ambiguous dynamic typings. By aggressively intercepting these failure modes via a Redis-backed cross-agent state tracker, strict Pydantic mode="before" sanitization, and localized semantic entropy monitoring, we transform stochastic failure loops into deterministic, observable exits.
Implementing these safeguards prevents runaway token burn, eliminates silent retry loops, and preserves the fidelity of the 128k context window, ensuring the Manager Agent retains the capacity to actually orchestrate rather than endlessly re-delegate.
If your engineering team is building complex, hierarchical agent topologies and encountering systemic failures at scale, contact Azguards Technolabs for a comprehensive architectural review. We build the infrastructure that makes AI orchestration strictly deterministic.
Would you like to share this article?
🔎 Need Help Debugging a Multi-Agent System?
From runaway token usage to unstable orchestration logic, we diagnose and fix complex AI system failures in production environments.
Talk to an AI Systems Engineer